Crossformer(2023 ICLR)
引言
MTS 介绍
MTS(multivariate time series)中每一个维度都代表一个时间序列,且维度与维度之间是相互关联的,利用其它维度的历史信息可以更好地预测当前维度的信息。例如预测气温,不仅可以依据历史气温的信息,还可以依据历史风速的信息。
MTS需要考虑两个方面的依赖性:cross-time dependency(时间依赖性)和 cross-dimension dependency(维度依赖性)。
提出问题
cross-dimension dependency:
- CNN
- GNN
cross-time dependency:
- Transformer-based
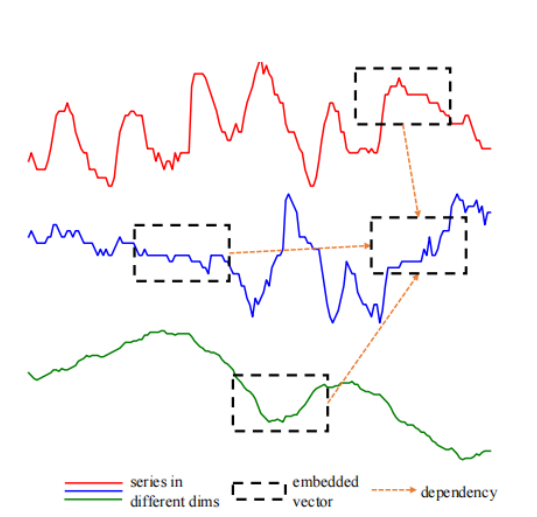
现有的 Transformer-based 模型没有充分(显式)地利用上 cross-dimension dependency,将多元时间序列当做单时间序列处理,如图所示:

论文贡献
- 指出现有的 transformer-based 模型没有充分利用上 MTS 中的 cross-dimension dependency
- 提出 Crossformer 模型:第一个显式利用上 cross-dimension dependency 的 Transformer-based 模型
- 进行了大量实验论证 Crossformer 模型的效果
相关工作
基于统计模型(VAR 和 VARMA)的 MTS
假定 cross-time dependency 和 cross-dimension dependency 是线性关系
基于其它神经网络(CNN、RNN、GNN)的 MTS
难以处理 long-term 依赖
基于 Transformer 的 MTS
主要研究方向都在 cross-time dependency 以及降低模型处理的时间复杂度
Vision Transformer
ViT 在 CV 领域取得不错的效果,启发论文作者设计 DSW
Crossformer 模型的设计
设计 DSW embedding(dimension-segment-wise embedding)
目的
显式利用MTS中的 cross-dimension dependency
分析
Transformer 一开始用于 NLP 领域,每个词对应一个向量。但是对于 MTS 来说,一个时间步对应一个 attention value 所包含的信息不够。所以现有的基于 Transformer 的模型直接应用于 MTS 考虑还不够。
针对 MTS 的特点:时域(time domain)附近的 attention value 是相近的。时间维度上按 segment 进行划分不仅可以提高局部相关性,还可以降低计算复杂度。

具体设计
MTS 中每个 dimension 的时间序列被划分为多个 segment,每个 segment 对应一个 feature vector。
$$
x_{1:T}= { x_{i,d}^{(s)}| \leq i \leq \frac{T}{L_{seg},},1 \leq d \leq D } \
x_{i,d}^{(s)}= { x_{i,d}= { x_{t,d}|(i-1)\times L_{seg}<t \leq i \times L_{seg}} \
h_{i,d}=Ex_{i,d}^{(s)}+E_{i,d}^{(pos)}
$$
MTS 的编码结果 $H= \left{ h_{i,d}|1 \leq i \leq \frac{T}{L_{seg}},1 \leq d \leq D \right} $ 是一个 2D 数组

设计 TSA(two-stage-attention)layer
目的
用来高效处理 DSW 中的 cross-time dependency 和 cross-dimension dependency
分析
- Vision Transformer 中将 2D array 摊平成 1D vector,然后作为模型的输入。因为图片的 height axe 和 width axe 有着相同的含义,所以是可交换的,但是对于 MTS 而言,time axe 和 dimension axe 的含义是不同的,所以应该差别对待。
- 直接在 $H_{D \times L}$ 上应用 self-attention 的计算复杂度为 $O(D^2 L^2)$
具体设计
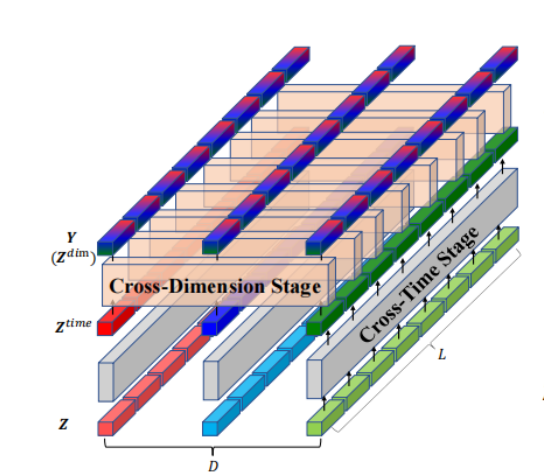
Cross-Time Stage
对单个维度的时间序列计算multi-head self-attention(MSA),所有维度共享参数,所以上图的 Corss-Time Stage 灰色块实际上看做是同一个。
$$
\hat{Z}{:,d}^{time} = LayerNorm(Z{:,d}+MSA^{time}(Z_{:,d},Z_{:,d},Z_{:,d})) \
Z^{time}=LayerNorm(\hat{Z}^{time}+MLP(\hat{Z}^{time}))
$$
单个维度的 self-attention 计算的时间复杂度为 $O(L^2)$,因此 Cross-Time Stage 的时间复杂度为 $O(DL^2)$
L 可以通过对 segment 分片的大小来进行控制
Cross-Dimension Stage
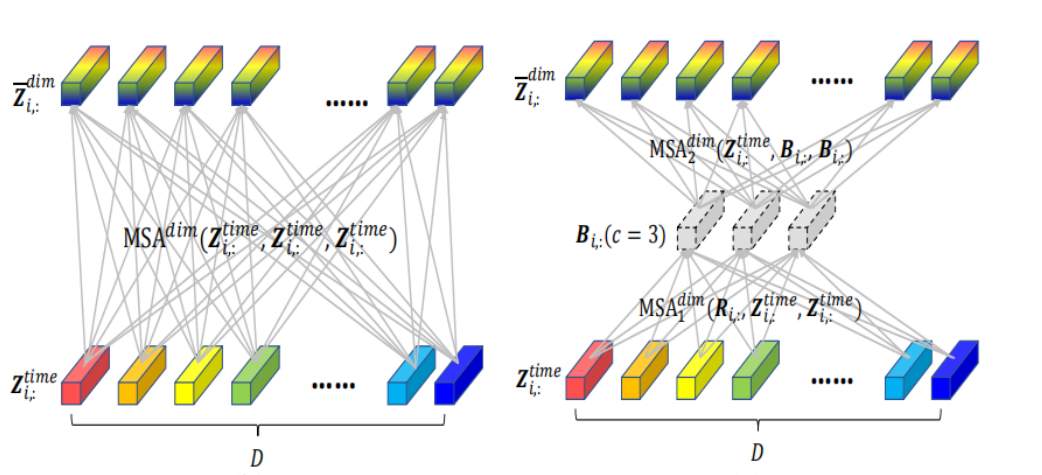
常规计算 self-attention 的时间复杂度为 $O(LD^2)$,D 的值无法通过分片手段来进行压缩,因此通过 FC 层(router 机制)来整合一个时间步中各个维度的信息(即$Z_{i,:} \to B_{i,:}$),其中 $c \ll D$ 。
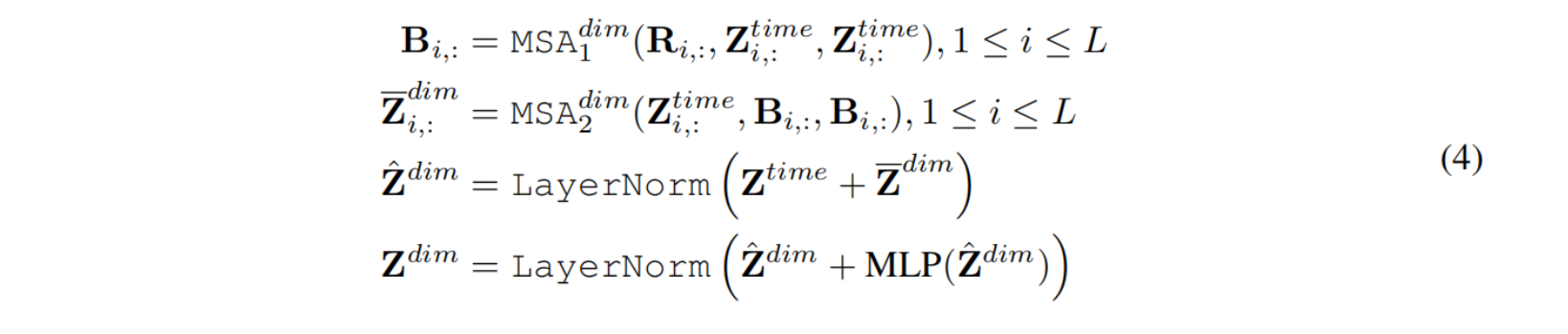
设计 HED(Hierarchical Encoder-Decoder)
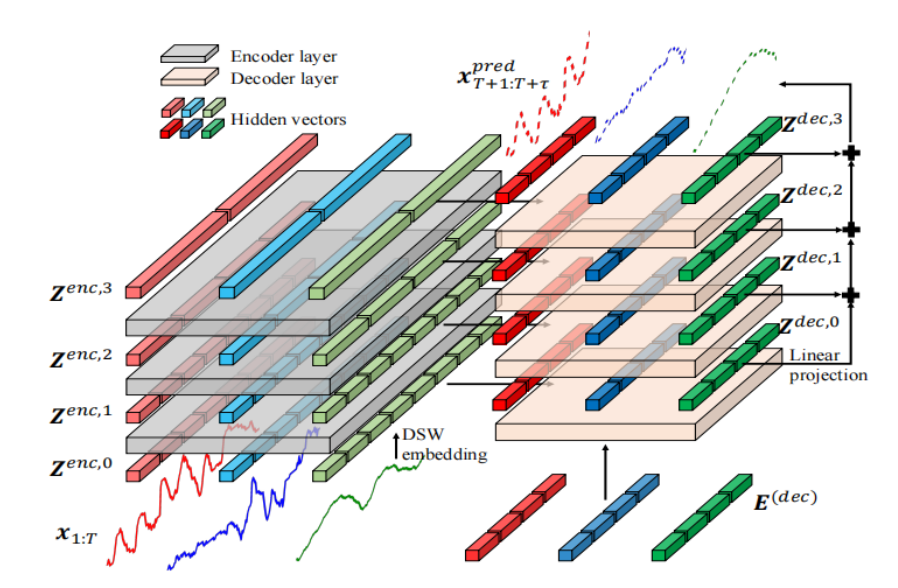
通过 DSW 对 MTS 进行 embedding,通过 TSA 来堆叠 Encoder 和 Decoder
Encoder
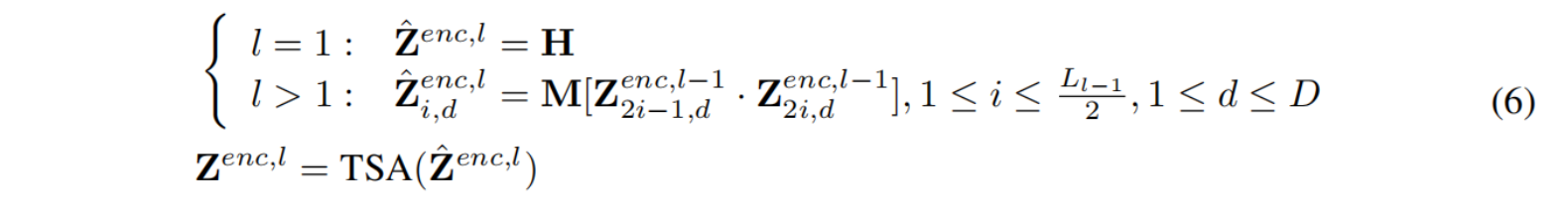
Decoder

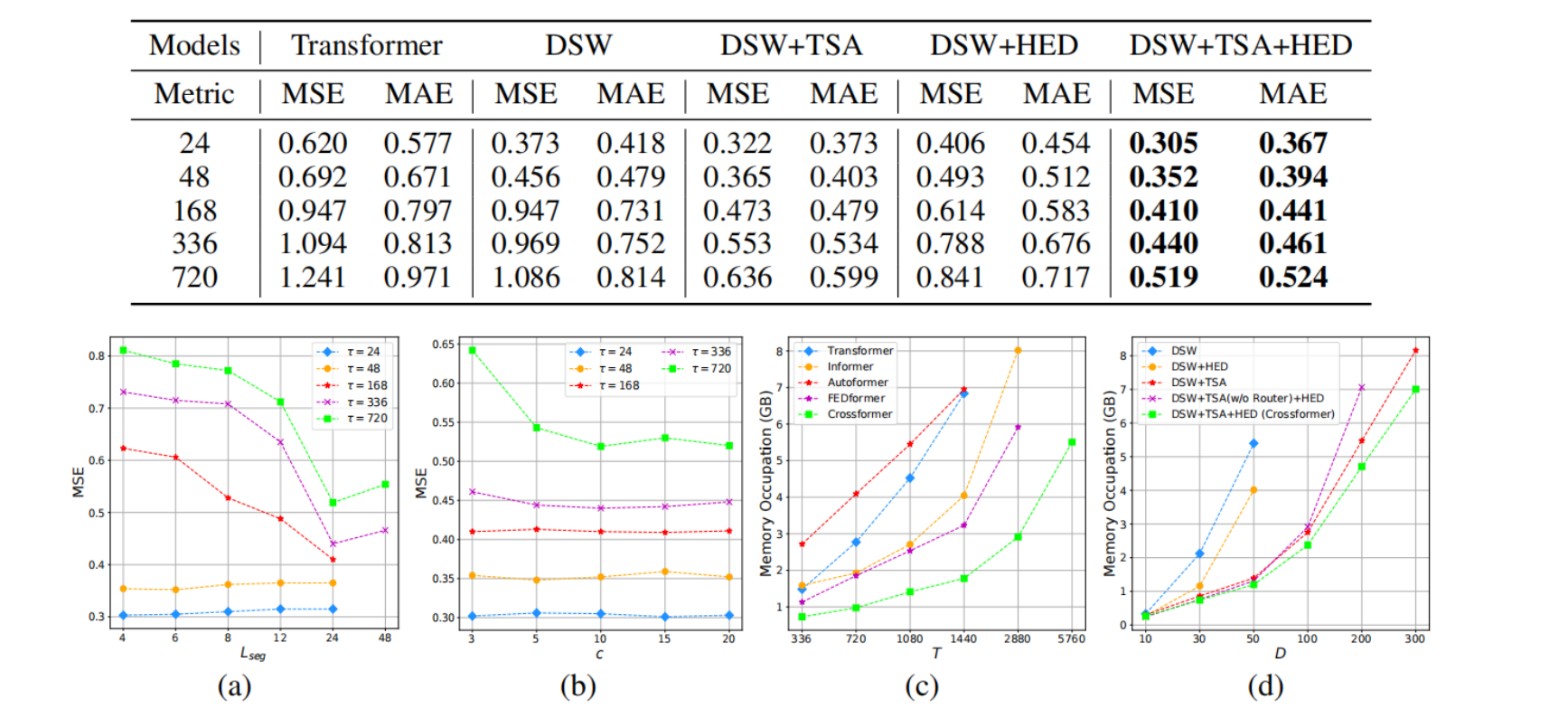
实验
略