social network(社交网络): graphs of people
Graphs are powerful structures useful not only for representing connected information, but also for supporting multiple types of analysis.
应用场景
- 推荐系统Recommendation
- 欺诈检测Fraud detection
性能
精度accuracy
速度speed
例如推荐系统中提供预测的速度会影响整个产品的可用性
图的优势:
- 以一种易于理解和易于访问的方式来表示数据representing data in a way that is easily understandable and easily accessible
- 图对于数据的表示更快、更准确、更有效(全面)
- 图算法也是一种有效的机器学习工具:graph community detection 和 page rank 算法
学习是将经验转化为专业知识或知识的过程,学习是要提升泛化能力,要能举三反一。模型要能够归纳推理
从错误的数据学习到错误的结果,无论使用的算法如何高级或者性能如何优异
为图上的顶点和边分配不同的语义来表示不同的网络:设计网络、交通网络、信息网络等等
contextalized word embedding(CoVe:Context Vector):看完一整个句子后,才对每个单词进行编码。这样能够获取上下文信息,避免相同的单词一定输出相同的向量(普通的word2vec模型没有考虑语义信息,例如,单身狗和一只狗)
输入:
- one sentence
- multiple sentences
输出:
one class
每个token的embedding vector平均,或RNN,…
class for each token
copy from input
例如,从文章里面提取答案,即答案完完全全从文章材料中获得。
general sequence
如何 pre train
使用翻译任务作为预训练的任务,可以如实地呈现词语的语义信息,不会受到具体的下游任务的影响而造成embedding vector。但是需要成对的训练资料,英文资料和翻译后的中文资料,这给训练任务的数据收集造成困难。
因此提出self supervised learning技术,希望通过没有标注的文本来进行训练。self supervised learning是将训练数据x产生两个方向,分别是x‘和x’‘,其中x’作为模型的输入,而x’‘作为模型的输出。在NLP领域,用预测下一个token的任务来取代翻译任务作为模型预训练过程中的任务,此时有一个句子x(token1,token2,…,tokenn),将token1输入到模型中,其目标输出是token2,此时输入和目标输出都来源于原始的数据x中。
和时间序列一样,训练过程需要使用self-attention时需要使用mask,来防止模型直接使用后面的输入来作为前一个时刻的目标输出(这是self supervised的trick,但是不希望pre train的模型只学习到这个,因为没有泛化能力,所以需要使用mask来防止pre train的模型在训练过程中“偷看”答案)
BERT中似乎也有重构损失(reconstruction loss)
用pre-train的模型来作为encoder,用具体的task-specific的模型作为decoder。但是这样会导致task specific模型没有被预训练过
如何 fine tune
fine-tune阶段既可以将pre-train的模型中的参数固定住(fix),将pre-train模型作为一个特征提取器(feature extractor);也可以将pre train模型和task specific模型一起fine tune(微调),一般而言,一起fine tune的效果可能更好,但是一起fine tune存在的问题是pre train模型会跟下游任务相关,导致一个下游任务产生一个pre train模型的参数。现在的想法是,下游任务对pre train模型造成的影响通过另外一个小模型体现出来(Apt适配器部分),对于一个具体的下游任务只需要保存小模型Apt适配器即可.
Fastformer(2021 反例)
宣称使用 O(n) 的加法注意力机制
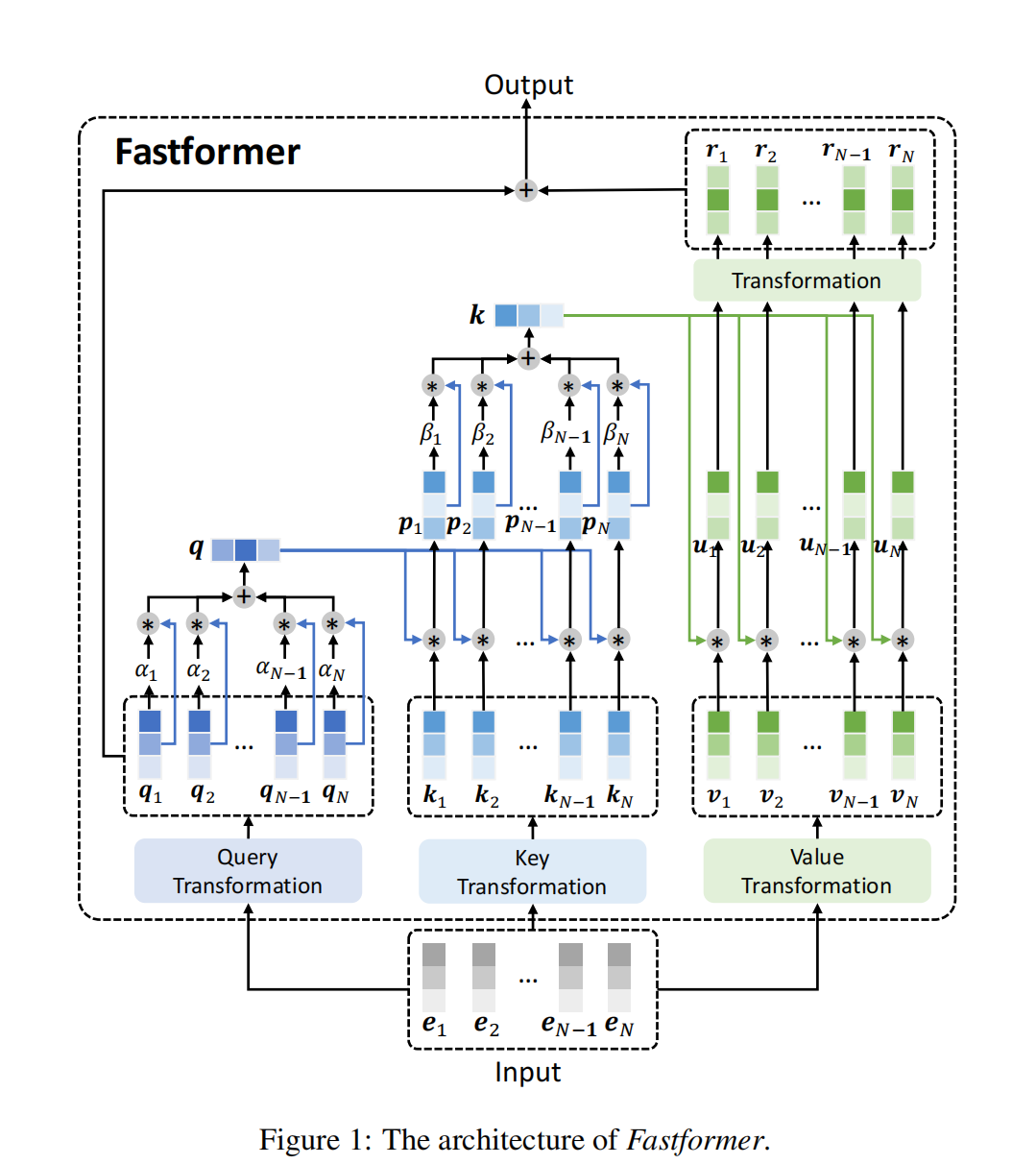
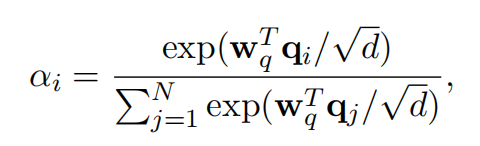
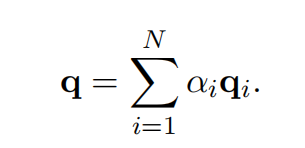
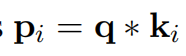
批评点:
- 不是attention机制,w在模型完成之后就定死了,而attention机制中qk都是跟随序列可变的,本质上是MLP
- 没有进行消融实验验证 最后一步拼接操作
+的有效性,有些莫名其妙
Specformer(2023 ICLR)
对图特征的利用方式分类
spatial GNN
采用消息传递框架(message passing framework),通过GCN来传播局部信息
- GAT
- MPNN
可能存在过度平滑和过度挤压的问题,GCN的层数不能太深,一般2到3层,需要平衡局部信息和全局信息,这也是spatial GNN研究的一个重点
spectral GNN
通过在图的拉普拉斯矩阵上应用spectral filter来替代GCN,利用图拉普拉斯矩阵的谱在谱域内进行卷积。
- 一个主流方向是利用不同的正交多项式(正交基)来近似滤波器,依赖对称矩阵的对角化来避免高代价的矩阵的谱分解
- 另一个方向多多少少需要进行谱分解,例如SpectralCNN、LanczosNet。这个方向通过神经网络参数来表示spectral filter,因此比预定义的正交基有更强的表示能力,但是这种滤波器还是不能捕获多个特征值之间的依赖关系。
Graph Transformer
Transformer 和 GNN 有着强关联,Transformer的attention weight可以看做是节点和节点之间的邻接矩阵。Graph Transformer仍然属于spatial GNN的一类。例如,Graphormer、SAN、GPS(graph signal process)。spatial attention 相较于 spectral attention 有一些限制,参考文献Bastos 2022。
spectral GNN 目前发展不如 spatial GNN,原因有下:(引出关键是对spectral filter的设计,即论文贡献)
- 现有大多数的 spectral filter 本质上是标量到标量的函数(scalar-to-scalar function),具体来说,将单个特征值(eigenvalue)作为输入,对所有的特征值使用相同的 spectral filter,这种过滤机制忽略了嵌入在spectrum(频谱)中的丰富信息。例如,从spectral GNN的理论中,特征值为0的代数重数表示图中连通分量的个数,但是这些信息不能被scalar-to-scalar filter捕获到。
- spectral filter通常使用固定阶的标准正交基(切比雪夫多项式、图小波等)来表示,从而避免高代价的拉普拉斯矩阵的谱分解。虽然正交基有着很好的性质,但是固定阶(代表截断)的这种近似的表达能力比较差,可能会严重限制图表示的学习。
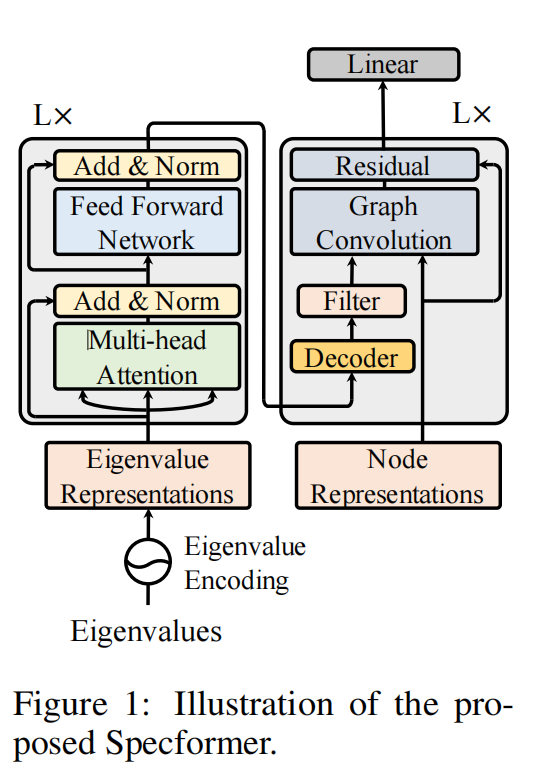
利用 Transformer 来捕获所有特征值的大小和相对差异
如果直接使用特征值(标量scalar)来计算attention map,那么self-attention受到严重限制。所以使用一个encoding function使其从标量转换成向量
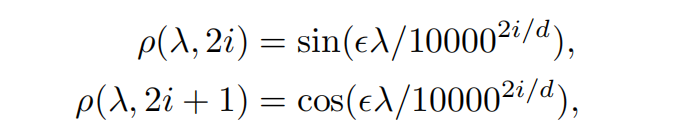
该函数的三个优点:
- 能够捕获特征值的相对频移(relative frequency shifts of eigenvalues ???),从标量转换成向量
- 波长范围是2pi到 10000*2pi,构成特征值的多尺度表示(???)
- 能够通过调节参数e来控制特征值的影响,并且该影响是巨大的,通过实验进行说明
EE(eigenvalue encoding)和 PE(position encoding)相似,PE描述的是spatial domain中的位置信息,EE代表的是spectral domain中连续特征值(continuous eigenvalues)的信息,但是将PE应用于特征值的位置信息上会破坏permutation equivariance properties(排列等方差性),损害学习能力。
一个Zm对应经过decoder之后对应一个特征值的spectral filter,然后重构
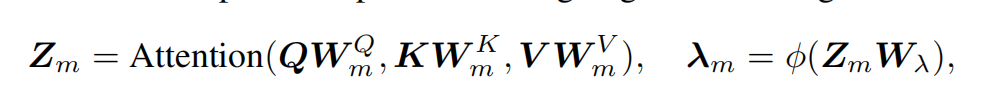
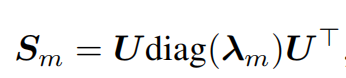
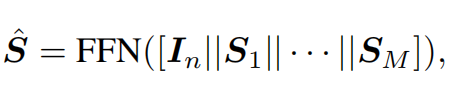
和其它模型的对比
和Polynomial GNN对比:
Polynomial GNN使用多项式(x,x^2,x^3,…)来进行表示。
- Specformer更通用,Specformer可以近似表示任何多项式,多项式是Specformer的一种特例。
- Specformer更灵活,Polynomial GNN对于所有的特征值都使用共享的function,而Specformer是每个特征值使用一个专门的function
和MPNN对比:
- MPNN通过GCN聚合局部的邻居节点的信息,计算效率高,但是捕获全局信息的能力弱(存在过度平滑的问题)
- Specformer由于使用了稠密的特征值,本质上是非局部的(no local)。
全局信息 > 局部信息吗?Specformer能够捕获全局信息就更优秀?
和 Graph Transformer对比:
现有的Graph Transformer在graph-level tasks上效果好,但是在node-level tasks上没有竞争力,例如node classification(最近一些研究在证明这个现象)。而Specformer 在这两类任务上表现都良好。




