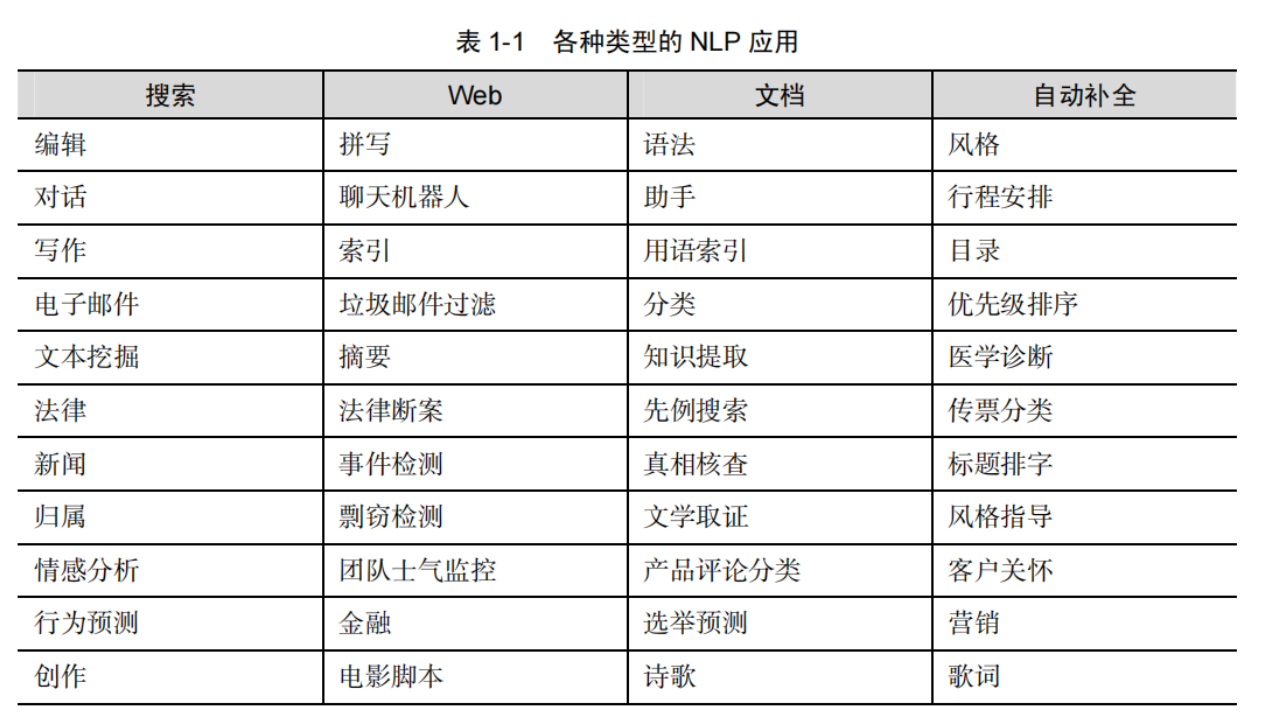
NLP 概述
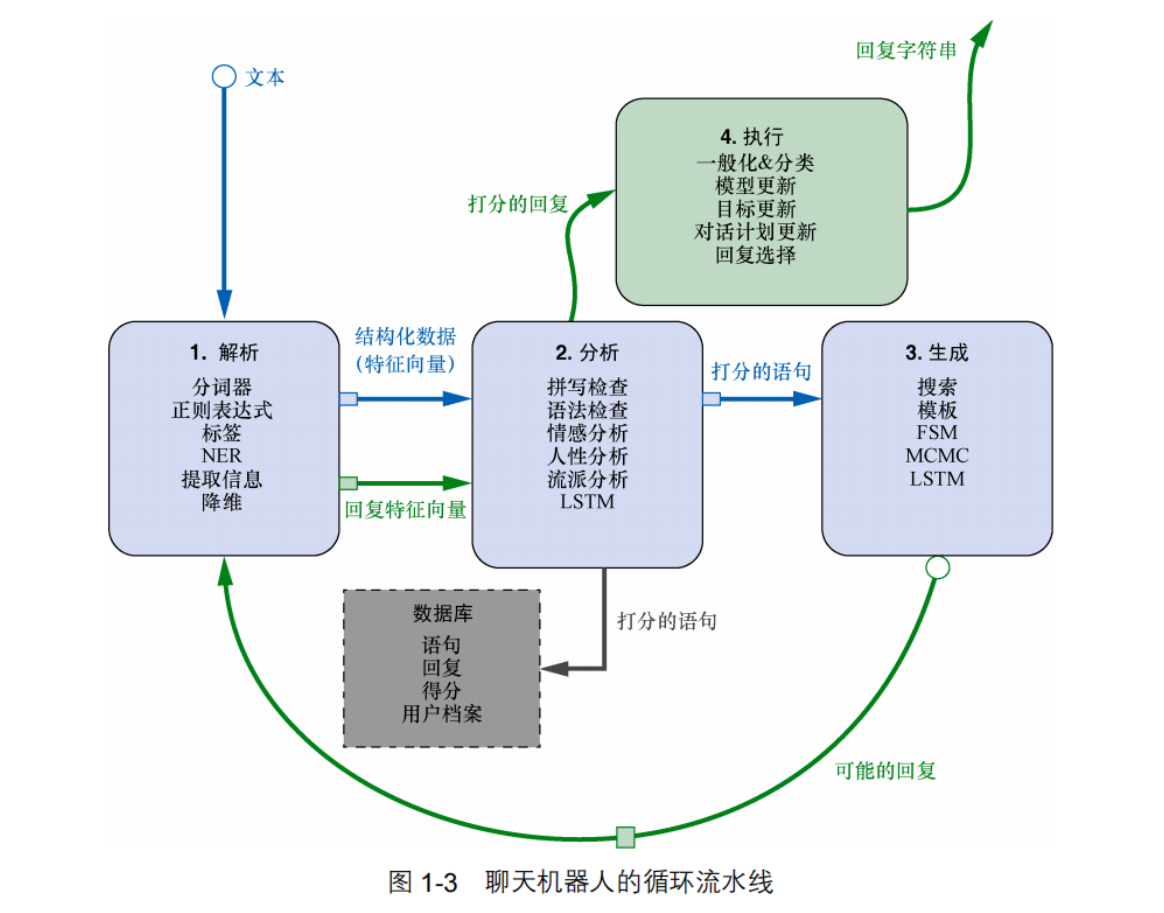
自然语言处理系统常常被称为“流水线”(pipeline),这是因为该系统往往包括多个处理环节,其中自然语言从“流水线”的一端输入,处理后的结果从另一端输出。
| 语音识别 | 语言到文本 |
| 语音生成 | 文本到语音 |
一旦从自然语言中提取出结构化的数值型数据,即向量化表示之后,就可以利用各种数学工具和机器学习工具。我们可以使用类似于将三维物体投影到二维计算机屏幕的线性代数的方法,让计算机能够解释和存储语句的“含义”,而不仅仅是对其中的词或字符进行计数。语义分析和统计学一起可以有助于解决自然语言的歧义性,歧义性是指词或短语通常具有多重含义和解释,例如:看病的是张三。
构建自己的词汇表(分词)
- 将文本切分成词或词条(n-gram)
- 处理非标准的标点符号和表情符号(例如社交媒体帖子上的表情符号)
- 利用词干还原和词形归并方法来压缩词汇表
- 构建语句的向量表示
- 基于手工标注的词条得分构建情感分析工具
第一件事是需要一个强大的词汇表,使用的技术只涉及词、标点符号和数值,但是这些技术可以推广到任何其他有意义的单元,例如ASCII表情符号、Unicode表情符号和数学符号等。
本章将给出将输入串切分成词的直接算法,同时我们还可以提取出连续 2 个、3 个、4 个甚至 5 个词条组成的词对、三元组、四元组和五元组。这些语言单位称为 n-gram(n 元)。连续两个词称为 2-gram(bigram),连续 3 个词称为 3-gram(trigram),连续 4 个词称为 4-gram,其余以此类推。
在自然语言处理中,从文本中产生其数值向量实际是一个特别“有损”的特征提取过程。尽管如此,词袋(bag-of-words,BOW)向量从文本中保留了足够的信息内容来产生有用和有趣的机器学习模型。
一旦从文档中确定好要加入词汇表中的词条之后,需要使用正则表达式工具来将意义相似的词合并在一起,这个过程称为词干还原(stemming)。
词干还原
所谓词干还原,指的是将某个词的不同变化形式统统“打包”到同一个“桶”或者类别中。
要将“ending”中的动词后缀“ing”去掉,那么就需要有个称为“end”的词干来表示上面两个词。同样,我们将词“running”还原成“run”,于是这两个词可以同等对待。当然,上述处理过程实际上有些棘手,因为“running”中要去掉的不仅仅是“ing”还有一个额外的字母“n”。还有,对于“sing”来说,我们期望不要去掉后面的“ing”而保留整个词,否则,最后就会得到单个字母“s”。
或者,大家再设想一下如何区分名词复数后面加的“s”(如 words)和词本身(如 bus 和 lens)后面就有的“s”。词当中一个个独立的字母或者词的一部分是否为整个词的意义提供了信息?这些字母是否可能产生误导?这两个问题的答案都是 yes。
利用分词器构建词汇表
在 NLP 中,分词(tokenization,也称切词)是一种特殊的文档切分(segmentation)过程。
文档切分可以是将文档分成段落,将段落分成句子,将句子分成短语,或将短语分成词条(通常是词)和标点符号。
于编译计算机语言的分词器通常称为扫描器(scanner)或者词法分析器(lexer)。某种计算机语言的词汇表(所有有效的记号合)构成所谓的词库(lexicon),如果分词器合并到计算机语言编译器的分析器(parser)中,则该分析器常常称为无扫描器分析器(scannerless parser)。
而记号(token)则是用于分析计算机语言的上下文无关语法(context-free grammar,CFG)的最终输出结果,由于它们终结了 CFG 中从根节点到叶子节点的一条路径,因此它们也称为终结符(terminal)。
| NLP | 编译器 |
|---|---|
| 分词器 | 扫描器、词法分析器 |
| 词汇表 | 词库 |
| 分析器 | 编译器 |
| 词条、词项、词、n-gram | 标识符、终结符 |
分词是 NLP 流水线的第一步,分词器将自然语言文本这种非结构化数据切分成多个信息块,每个块都可看成可计数的离散元素。这些元素在文档中的出现频率可以直接用于该文档的向量表示。
上面的词向量表示及文档的表格化表示有一个优点,就是任何信息都没有丢失。只要记录了哪一列代表哪个词,就可以基于整张表格中的独热向量重构出原始文档。即使分词器在生成我们认为有用的词条时只有 90%的精确率,上述重构过程的精确率也是 100%。因此,和上面一样的独热向量常常用于神经网络、序列到序列语言模型及生成式语言模型中。对任何需要保留原始文本所有含义的模型或 NLP 流水线来说,独热向量模式提供了一个好的选择。
即使将表格中的每个元素用单个位来表示,这个表格也超过了百万位乘以百万位的规模。在单个位表示一个元素的情况下,大概需要 20 TB 来存储上述小小书架上的书籍。即使对于长达几页的文档,词袋向量也可以用来概括文档的本质内容。
词袋向量:一个hashmap
计算向量之间的相似度
点积(内积)
词的重要度
将词表示为连续空间后,可以用更高级的数学方法对这些表示进行计算。我们的目标是寻找这些词的数值表示,这些表示在某种程度上刻画了次所代表的信息内容或重要度。
- 词袋
- n-gram
- TF-IDF




