测试题
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b"; // ab
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();// s4放入之前已经存在"ab", 因此s4放入失败, s6是StringTable中的字符串对象
System.out.println(s3 == s4);// false
System.out.println(s3 == s5);// true
System.out.println(s3 == s6);// true
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
System.out.println(x2 == x1);// false
String x3 = new String("z") + new String("w");
x3.intern();
String x4 = "zw";
System.out.println(x3 == x4);// true
}String 的基本特性
String 的不可变性
String s = "hello";
// 修改s变量指向的字符串对象, 而不是改变原本的字符串对象
s = "world";
// 通过StringBuilder的append()方法来拼接, 然后改变s的指向
s += "world";public class StringMain {
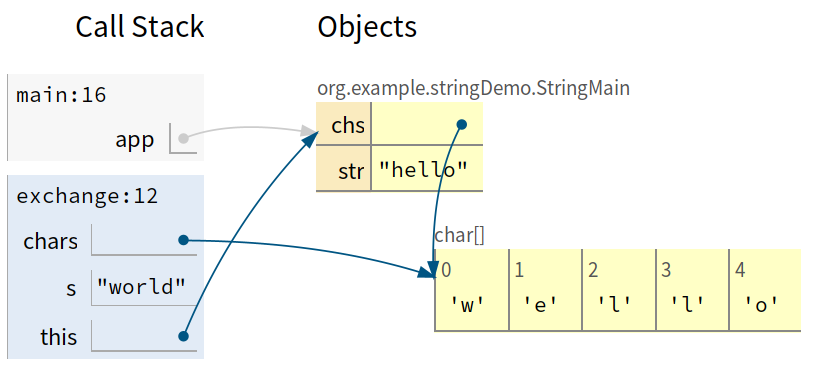
String str = new String("hello");
char[] chs = {'h', 'e', 'l', 'l', 'o'};
private void exchange(String s, char[] chars) {
// 1. 将app.str作为实参传入, 相当于s和app.str指向同一个字符串对象
// 2. s = "world" 是改变局部变量s的引用对象, 并没有对原本的引用对象"hello"产生影响
s = "world";
chars[0] = 'w';
}
public static void main(String[] args) {
StringMain app = new StringMain();
app.exchange(app.str, app.chs);
System.out.println(app.str);
System.out.println(app.chs);
}
}
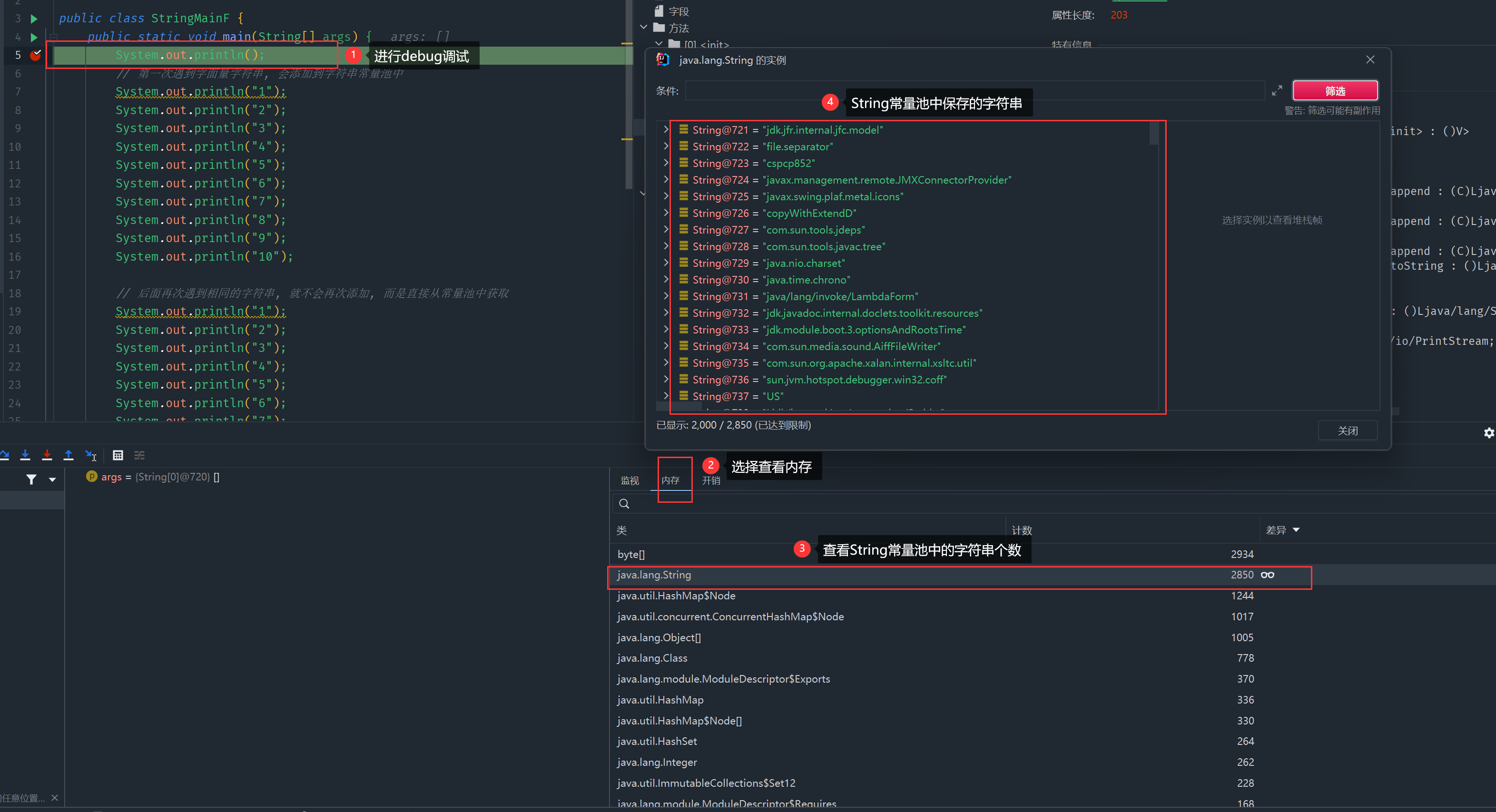
字符串常量池(String Pool)中不会存储两个相同内容的字符串
和Set的性质一样, 底层也是使用HashTable来实现的.
public class StringMain {
public static void main(String[] args) {
// 添加断点
System.out.println();
// 第一次遇到字面量字符串, 会添加到字符串常量池中, 调试时字符串计数会增加.
// 注意应该用运行完一行代码后的值来进行比较
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");
// 后面再次遇到相同的字符串, 就不会再次添加, 而是直接从常量池中获取, 此时字符串计数不再增加
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");
}
}
String的内存分配
8种基本数据类型和String类型提供了一个常量池. 常量池类似一个Java系统级别的缓存.
在Java8中字符串常量池在堆中.
// 方式一: 通过双引号声明的String对象会直接存储在常量池中
String s = "hello";
// 方式二: 使用intern()方法添加到字符串常量池中
字符串拼接
- 常量 + 常量 => 编译期优化 => 常量池
- 变量 + 常量(变量) => StringBuilder() => 堆
StringBuilder类的toString()方法会通过new String()来在堆空间创建一个字符串
常量拼接
注意final修饰的量会在编译期优化, 相当于符号常量
Java源代码
public class StringMain {
public static void main(String[] args) {
String s1 = "a" + "b" + "c";
String s2 = "abc";
// true. 由于编译期优化, 本质上String s1 = "abc";
System.out.println(s1 == s2);
}
}字节码反编译的Java代码
public class StringMain {
public StringMain() {
}
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
}
}class字节码
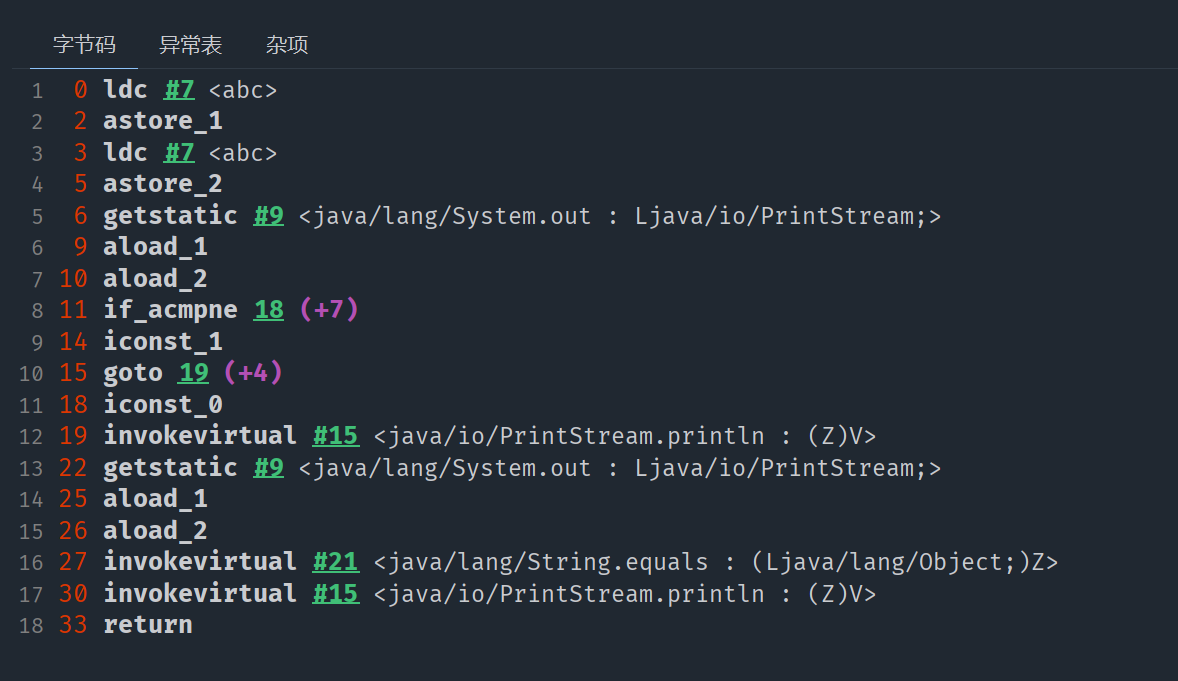
变量拼接
只要拼接过程中出现变量, 那么就属于变量拼接
Java源代码
public class StringMain {
public static void main(String[] args) {
String s1 = "javaEE";
String s2 = "hadoop";
// 变量 + 常量
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
// 变量 + 变量
String s7 = s1 + s2;
}
}class字节码
注: 使用Java8
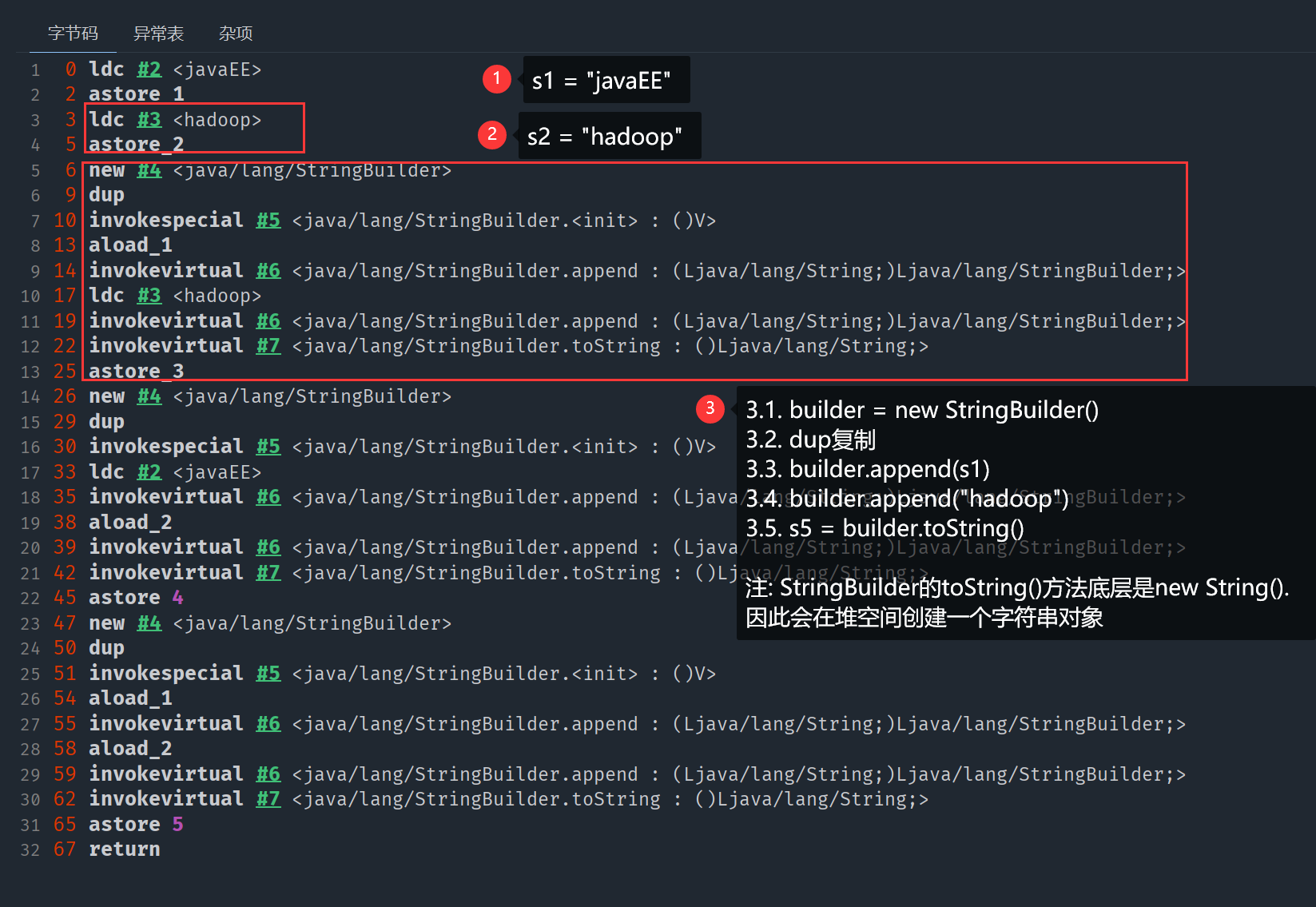
正确使用 StringBuilder 提高效率
public class StringMain {
public static void func01(int counts) {
String s = "";
for (int i = 0; i < counts; i++) {
// 每次拼接都会创建一个StringBuilder对象, 完成append()和toString()操作, 重复counts次
// 每次toString()都会创建一个新的字符串
// 过多的String对象和StringBuilder对象需要回收, 增加了垃圾回收的负担
s += "a";
}
}
public static void func02(int counts) {
// 只会创建一个StringBuilder()对象, 不会将每个中间临时结果都保存成一个字符串
StringBuilder builder = new StringBuilder(counts);
for (int i = 0; i < counts; i++) {
builder.append("a");
}
}
public static void main(String[] args) {
int counts = 100000;
long begin;
begin = System.currentTimeMillis();
func01(counts);
System.out.println("func01: " + (System.currentTimeMillis() - begin));
begin = System.currentTimeMillis();
func02(counts);
System.out.println("func02: " + (System.currentTimeMillis() - begin));
}
}测试
public class StringMain {
public static void main(String[] args) {
String s1 = "javaEE";
String s2 = "hadoop";
// 常量 + 常量
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
// 变量 + 常量
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
// 变量 + 变量
String s7 = s1 + s2;
System.out.println(s3 == s4);// true
System.out.println(s3 == s5);// false
System.out.println(s3 == s6);// false
System.out.println(s3 == s7);// false
System.out.println(s5 == s6);// false
System.out.println(s5 == s7);// false
System.out.println(s6 == s7);// false
}
}intern() 与字符串常量池(重点图解)
将堆中字符串放入到常量池中
- 如果常量池中已经存在该字符串, 那么intern()会返回该字符串在常量池中的地址
- 如果常量池中不存在该字符串, 那么会在常量池中创建一个引用变量, 指向字符串已经在堆中分配的内存空间. 即放入常量池并不是在常量池中新开辟一片内存空间来保存这个字符串对象, 而是复用堆空间中已有的字符串对象.
s.intern() == t.intern() <=> s.equals(t)
注:在 JDK 1.8 之前,
intern()放入字符串时也会创建一份副本,然后将副本放入到 StringTable 中。在 JDK 1.8 及以后,不会创建额外的字符串副本对象。
字符串常量池中存在相同内容的字符串
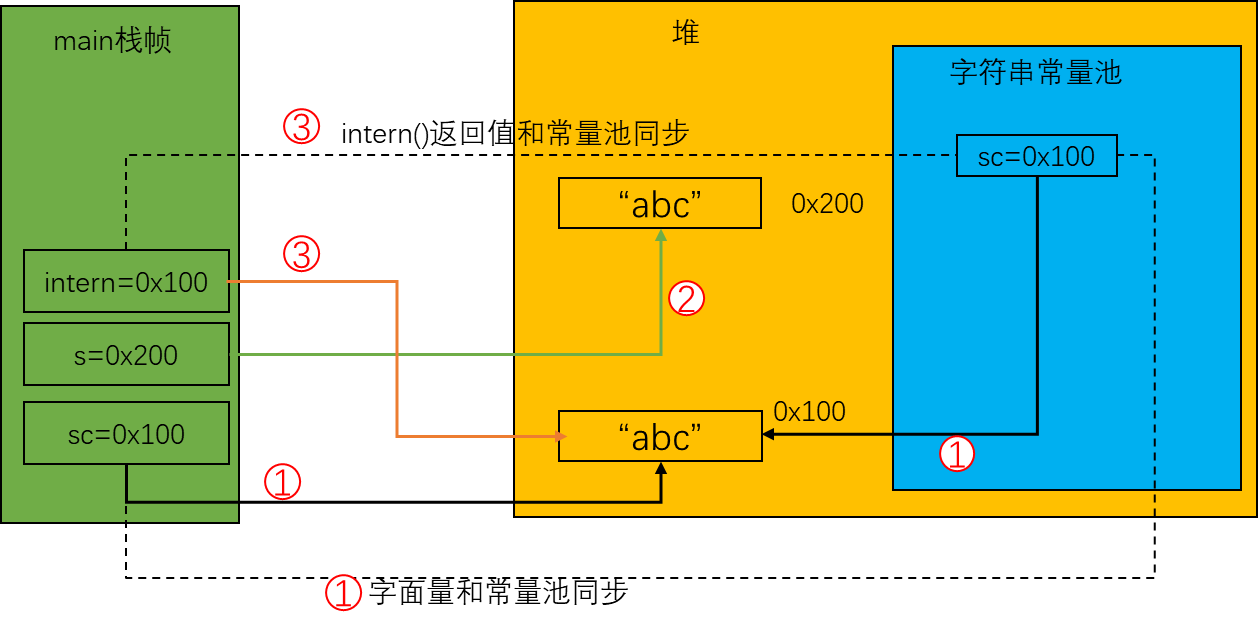
public class StringMain {
public static void main(String[] args) {
// "abc"已经放入到字符串常量池中
String sc = "abc"; // (1)
StringBuilder builder = new StringBuilder();
String s = builder.append('a') // (2)
.append('b')
.append('c')
.toString();
// 因为常量池中已经有相同内容的字符串, 因此返回sc的值
// 问: 这里如何快速判断s字符串是否出现在字符串常量池中呢? 通过挨个字符比较吗? 那样效率太低了吧. 通过hashCode可能会有hash冲突啊, 相同hashCode也不能说明两个字符串内容相同啊
// 答: 通过equals()方法
String intern = s.intern(); // (3)
System.out.println(sc == intern); // true
System.out.println(sc == s); // false
System.out.println(s == intern); // false
}
}
字符串常量池中不存在相同内容的字符串(易错)
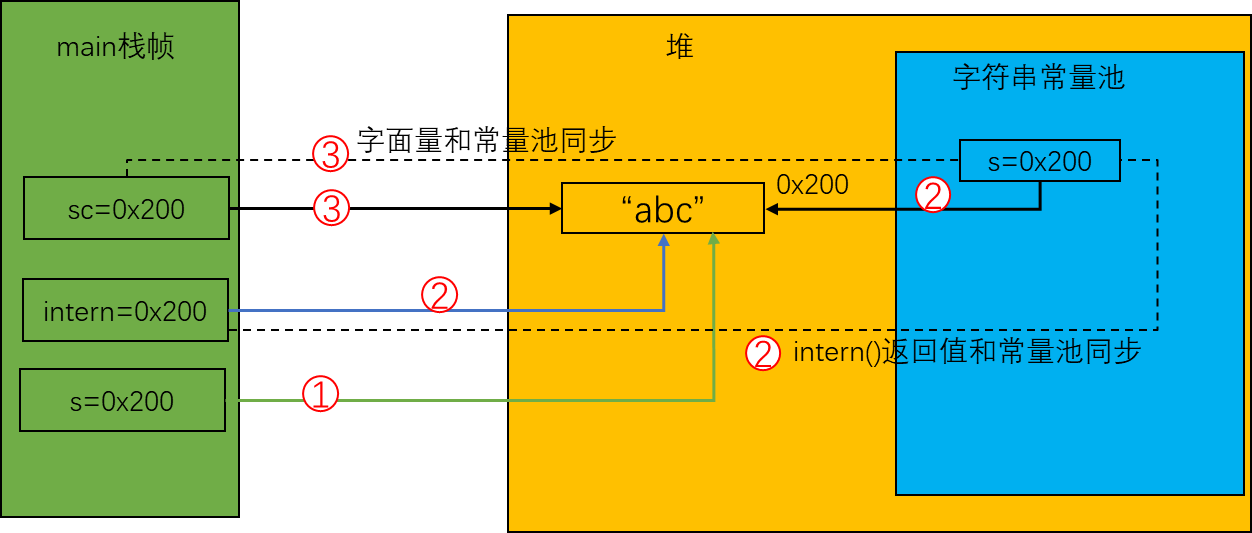
public class StringMain {
public static void main(String[] args) {
public static void main(String[] args) {
StringBuilder builder = new StringBuilder();
// s指向是堆空间的一个字符串对象"abc", 因为是通过StringBuilder的toString()方法生成的字符串对象, 而toString()底层又是调用new String(char[], int, int), 所以"abc"以字符数组['a','b','c']的形式存在于StringBuilder对象的value属性中, 并不会将"abc"记录到字符串常量池中. 因此这里创建了一个s = "abc", 但是
String s = builder.append('a') // (1)
.append('b')
.append('c')
.toString();
// 将s指向的字符串对象放入到字符串常量池中, 之后对于"abc"的引用都是引用s指向的字符串对象
String intern = s.intern(); // (2)
// sc一定指向字符串常量池中指向的字符串对象
String sc = "abc";
System.out.println(sc == intern); // true
System.out.println(sc == s); // true
System.out.println(s == intern); // true
}
}
new String() 到底创建了多少个对象
public class StringMain {
public static void main(String[] args) {
// 1. 字面量"x" =>
// 1.1. 如果字符串常量池中不存在"x", 那么会在堆空间中创建一个字符串对象"x"(假设地址为0x100), 并自动放入到字符串常量池中
// 1.2. 如果字符串常量池中存在"x", 那么不会再次创建对象(说明之前已经创建过), 直接返回即可
// 2. new String("x") => 堆空间中再创建一个字符串对象"x"(假设地址为0x200), 则s1 = 0x200
String s1 = new String("x");// 创建两个字符串对象
String s2 = "y"; // 创建一个字符串对象, 并放入到字符串常量池中
String s3 = new String("y");// 只创建一个字符串对象
// 1. + => 创建一个StringBuilder对象
// 2. 字面量"a" => 创建一个字符串对象"a", 并放入常量池
// 3. a = new String("a") => 在堆空间中再次创建一个字符串对象"a"
// 4. append(a) => 添加到字符数组中 value = ['a',...]
// 5. 字面量"b" => 创建一个字符串对象"b", 并放入常量池
// 6. b = new String("b") => 在堆空间中再次创建一个字符串对象"b"
// 7. append(b) => 添加到字符数组中 value = ['a', 'b', ...]
// 8. builder.toString() => 底层调用new String(char[], int, int)再次创建一个字符串对象
String s4 = new String("a") + new String("b");
}
}什么时候会放入字符串常量池
结论: 显式地出现了字面量就会放入到常量池中
public class StringMain {
public static void main(String[] args) {
// new String("hello")时已经将"hello"放入到字符串常量池中, 而s1是在堆空间中的一个引用变量
String s1 = new String("hello");
// intern()返回值和字面量都是从字符串常量池中获得, 因此是同一个对象
String s2 = s1.intern();
String s3 = "hello";
System.out.println(s1 == s3);
System.out.println(s1 == s3);
System.out.println(s2 == s3);
// "hello"和"world"作为字面量都保存在字符串常量池中, 但是"helloworld"并没有出现在字符串常量池中
// 这里是通过StringBuilder的toString()方法, 底层是new String(char[] value, int begin, int offset), 所以此时和new String("helloworld")还是存在差距.
// 通过chars[]方式生成的字符串, 并没有将该字符串放入到字符串常量池中, 因为使用的是字符数组.
// 对于StringBuilder中的append(String str), 会先获取str的字符数组, 然后再追加
String s4 = new String("hello") + new String("world");
// 将"helloworld"通过intern()方法添加到字符串常量池中, 因为s4是第一个, 所以常量池中保存的实际上就是s4这个堆空间的字符串对象
String s5 = s4.intern();
String s6 = "helloworld";
System.out.println(s4 == s5);
System.out.println(s4 == s6);
System.out.println(s5 == s6);
}
}证明 StringTable 所在的内存空间位置
在 JDK 1.7 之前,StringTable 在方法区中,而方法区在永久代中。而在 JDK 1.7 及以后,StringTable 在堆中。
验证思路:给 StringTable 中不断地添加字符串,当发生内存溢出时,查看报错信息显示是哪个区域的空间不足即可。
@Test
public void positionTest() {
ArrayList<String> tables = new ArrayList<>();
String s = "a";
for (int i = 0; i < 10000; i++) {
System.out.println(i);
String t = s + s;
s = t;
tables.add(s);
}
tables.forEach(System.out::println);
}StringTable 的应用案例
对于存在大量重复的字符串对象的场景,例如,收件地址,几乎一个学校上万人使用重复的字符串,放入 StringTable 和不放入 StringTable 的内存占用比例达到 10000:1。




